The fundamental problem with knowledge banks for AI agents isn't the knowledge—it's engagement. You can build the most comprehensive knowledge base in the world, but if agents don't consistently query it, the knowledge sits idle. That was the problem that led us to build the Agent Mesh.
We had a well-populated Knowledge Bank. Agents could query it. Sometimes they did. But "sometimes" isn't good enough when you're running dozens of autonomous agents across multiple codebases. The engagement problem—agents not reliably pulling relevant context from the KB—meant that institutional knowledge was being rediscovered from scratch, session after session.
The deeper issue is that you don't know what you don't know. How does an agent know what to search for if it hasn't encountered the problem yet? Traditional knowledge retrieval assumes the user (or agent) can formulate a good query. But the most valuable knowledge is often the kind you need before you realize you need it—the gotcha that saves you two hours of debugging, the configuration detail that prevents a production incident. By the time the agent encounters the problem and thinks to search, it's already wasted context rediscovering what a previous agent already learned.
When Agent A spends two hours investigating a codebase and learns that CloudSQL requires a proxy on port 15432, or that the auth system has two distinct patterns for web routes versus API routes—that knowledge evaporates when the session ends. Agent B, starting a similar task thirty minutes later, rediscovers the same facts from scratch. The agent was smart. The system was amnesiac.
The initial motivation for the Agent Mesh was simple: push knowledge to agents instead of waiting for them to pull it. Make the Knowledge Bank proactive rather than passive. If we can predict that a problem is coming based on an agent's behavioral trajectory, we can surface the solution before the problem fully manifests. But once we built the infrastructure for observing agent behavior in real time—capturing actions, embedding them, matching trajectories—two additional capabilities fell out almost for free: trajectory-based RAG (matching knowledge not by query similarity but by behavioral patterns) and multi-agent collision detection (spotting when two agents are working on overlapping problems and suggesting they coordinate).
What started as a solution to the engagement problem became a platform for passive multi-agent learning and collaboration. Here's how it works.
The Two Layers of the Mesh
The Agent Mesh operates in two layers, distinguished by how much the agent knows about it.
Layer 1: Active Mesh
Opt-in cooperation via the Knowledge Bank. Agents explicitly call mesh_narrate() to share discoveries with the Knowledge Bank and mesh_send_message() to communicate directly with other agents.
The agent decides what to share, when to share it, and who should receive it. This is straightforward but requires the agent to be aware of the mesh—and relies on it actually engaging with the KB.
Layer 2: Passive Mesh
Ambient awareness. Claude Code hooks fire automatically after every tool call and session end. The mesh observes actions, embeds them, and surfaces relevant knowledge—all invisibly.
The agent works naturally. The mesh learns from observation. No cooperation required.
The passive layer is where context engineering gets interesting. It's where the system stops relying on pre-configured retrieval and starts learning what agents need from how they behave.
Passive Observation: What the Hooks Capture
Every Claude Code session with the mesh enabled runs two hooks: a PostToolUse hook that fires after each tool call, and a Stop hook that fires when the agent finishes a turn.
The PostToolUse hook captures something specific: the agent's self-narration. Not the raw tool input ("Reading file: /app/models.py") but the agent's own description of what it's doing and why ("Investigating the ORM models to understand lazy loading behavior in the data access layer").
Each captured action goes through two paths simultaneously:
- Embedding and storage: The action text gets embedded (OpenAI's text-embedding-3-small[5]) and stored in a pgvector-indexed[4] table. This feeds both overlap detection and future pattern matching.
- Sequence window: The action is appended to a Redis sliding window of the agent's last 4 actions. This sliding window is the input to trajectory matching.
The hooks are debounced—8 seconds between API calls for PostToolUse, 15 seconds for Stop. This prevents flooding the backend while maintaining responsiveness. The entire observation pipeline has a latency budget of about one second, because context has to be returned before the agent's next action.
Trajectory-Aligned Pattern Matching
This is the core idea. Traditional RAG[6] retrieves knowledge based on semantic similarity to a query. The Agent Mesh retrieves knowledge based on semantic similarity to a sequence of actions—a trajectory.
The insight is simple: agents working on similar problems follow similar paths. An agent investigating database performance tends to look at query plans, then check connection pool settings, then examine index configurations. If a previous agent followed that same trajectory and discovered something important along the way, the mesh can surface that discovery to the current agent at the right moment—not because someone configured a retrieval rule, but because the behavioral patterns match.
How Patterns Are Stored
A sequence pattern is a group of 2–4 action descriptions linked to a knowledge bank entry. Each action is stored with its own embedding and a position index within the group.
Example Sequence Pattern (4-step)
How Matching Works
When the mesh needs to find relevant context for a working agent, it runs a four-phase pipeline. The agent's last N actions are embedded using text-embedding-3-small,[5] then scanned against the kb_sequence_patterns table using pgvector[4] to find candidate groups with cosine similarity above 0.40:
N actions → vectors
pgvector ANN search
Per-position similarity
Score, dedup, inject
For each candidate group, the agent's recent actions are aligned against the pattern's positions. Per-position cosine similarity is computed with recency weighting—later positions count more because they represent where the agent is, not where it was. Candidates are scored, filtered by threshold, checked against the delivery deduplication cache, and the top matches are injected as context. The full complexity analysis is in the Computational Complexity section below.
Recency Weighting: Why It Matters
The scoring algorithm doesn't treat all positions equally. A weighted area calculation gives later actions in the sequence more influence over the final score:
This captures an important intuition: if the agent is currently "Checking connection pool settings" and a stored pattern ends with "Checking connection pool settings"—that's a much stronger signal than matching only on the first action in the sequence. Matching where the agent is going matters more than matching where it's been.
Figure 1 below projects the trajectory alignment into 2D space for visual intuition—you can see the shaded area between the agent's path and the stored pattern, with later segments weighted more heavily. Figure 2 shows the formal generalization: the same algorithm operating on 1536-dimensional embedding vectors, with the complete mathematical derivation and a worked numerical example.
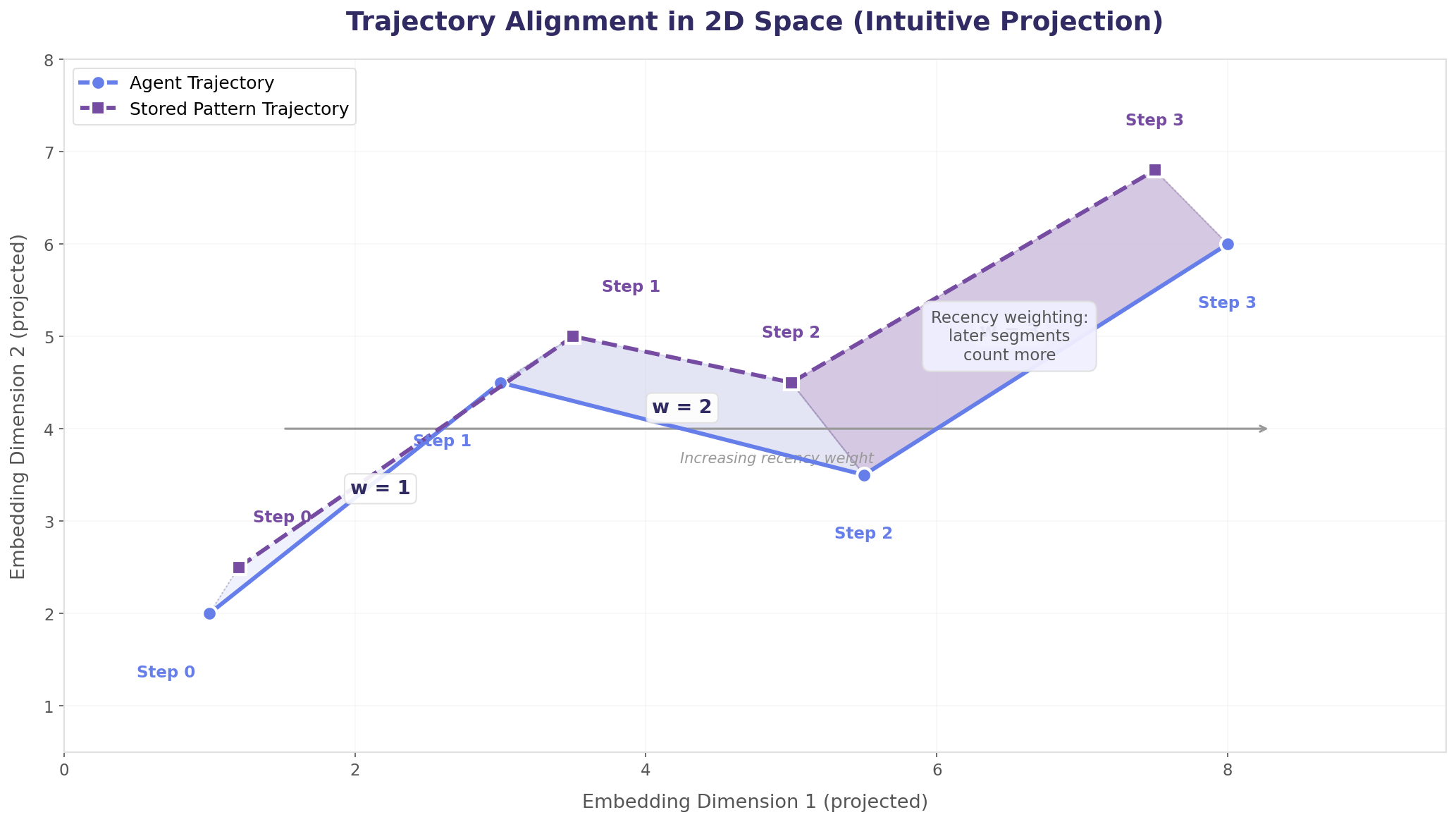
Figure 2: Formal Generalization — Trajectory Scoring in ℝ1536
Stored pattern embedding at position i: pi ∈ ℝ1536
Trajectory length: n positions (typically 2–4)
Scoring Example (4-step)
Computational Complexity: Query Time and Order
Trajectory matching runs on every agent action, so its computational cost directly constrains latency. Here's the breakdown by phase:
Embed
Scan
Align
Score & Deliver
The Feedback Loop: How the Mesh Learns
Trajectory patterns don't appear from nothing. They're created through a self-reinforcing feedback loop that is, itself, an exercise in automated context engineering.
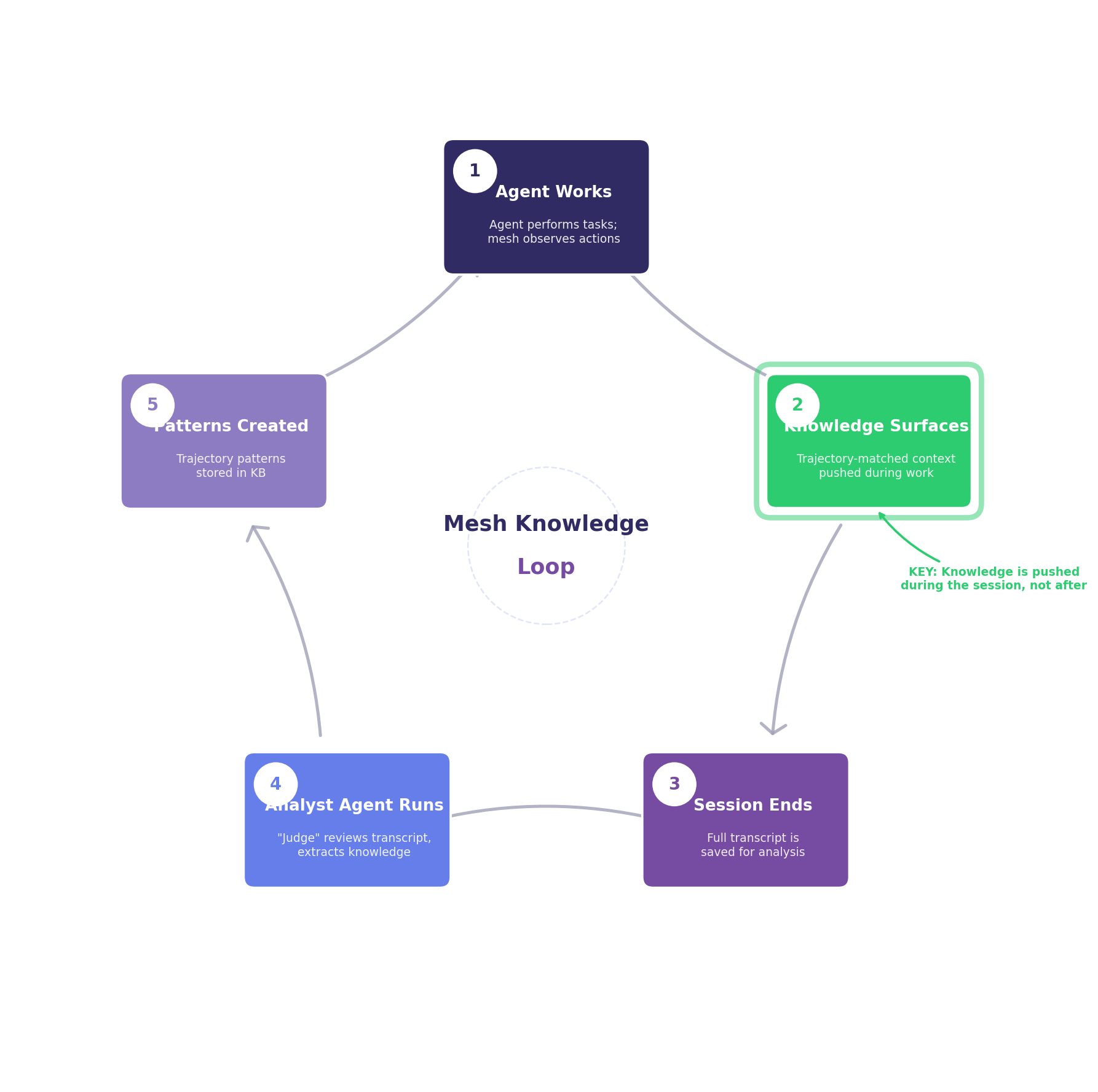
The analyst agent (step 4) is the judge—it reviews each session transcript and decides what constitutes permanent, reusable knowledge versus transient noise. It's instructed to extract intent-based narrations, not mechanical descriptions. "Investigating the ORM models to understand lazy loading" is a useful trajectory action. "Reading file: /app/models.py" is not. The quality of the mesh depends on the quality of its trajectory descriptions—which is why the system prefers agent self-narration over tool metadata at every stage.
Why This Is Different from RAG
The distinction is worth making explicit. Retrieval-Augmented Generation retrieves documents based on query similarity. The Agent Mesh retrieves knowledge based on behavioral trajectory similarity. The differences cascade:
Traditional RAG
Query-driven. Agent (or user) formulates a question. System retrieves relevant documents.
Reactive. Knowledge arrives after the agent knows it needs something.
Single-point matching. One query → one retrieval. No sequence awareness.
Configuration-heavy. Requires chunking strategy, embedding model selection, top-k tuning, reranking.
Trajectory Matching
Behavior-driven. Agent works naturally. System infers what knowledge is relevant from the pattern of actions.
Proactive. Knowledge arrives before the agent knows it needs it—or ever will.
Sequence-aware. Multiple actions aligned against stored trajectories. Temporal ordering matters.
Self-improving. Each session feeds back patterns that improve future sessions.
To be clear: the mesh also performs traditional KB search as a complement to trajectory matching. Both systems run in parallel on every action. But trajectory matching is what makes the mesh proactive—surfacing knowledge the agent hasn't thought to search for yet.
Multi-Agent Collision Detection
The passive mesh doesn't just surface historical knowledge—it also watches for real-time overlaps. When two agents are working on related parts of the codebase simultaneously, the mesh detects this through embedding similarity on their activity descriptions.
When Agent A is "investigating the auth middleware for API routes" and Agent B starts "examining authentication patterns in the route handlers," their activity embeddings land close together in vector space. The mesh flags the overlap and notifies both agents, suggesting they coordinate using the mesh_send_message() tool to avoid duplicating work or creating merge conflicts.

This is different from traditional orchestration, which assigns work top-down. Collision detection is bottom-up: agents work independently, and the mesh observes when their trajectories converge. No central coordinator needed. The agents choose whether and how to coordinate—the mesh just makes them aware of each other.
What We've Learned Building This
Running the Agent Mesh in production across multiple repositories has taught us several things that aren't obvious from the architecture alone.
Narration quality is everything. The entire system depends on agents producing useful self-narrations. When narration is mechanical ("Reading file X"), trajectory matching degrades to glorified file-based search. When narration is intent-rich ("Investigating lazy loading behavior to understand N+1 query patterns"), the trajectories become genuinely predictive. We strip tool prefixes and prefer assistant-generated descriptions over tool metadata for this reason.
Patterns need curation, not just creation. The mesh_kb_build automation generates patterns automatically, but not all generated patterns are useful. Some trajectories are too generic ("reading code, then writing code") and match everything. Low-utilization patterns need to be pruned over time. Context utilization tracking provides the signal for this, but the pruning itself is still a human decision.
Latency is the hard constraint. The entire observation-embed-match-deliver pipeline has to complete within the time between one agent action and the next. If context arrives too late, it's irrelevant. We run async processing in a background thread with a 1-second long-poll timeout, and pattern queries use pgvector indexes with window limits (4 recent actions, 10 candidate groups per embedding) to stay fast. Every optimization in the system is a latency trade-off.
Context Engineering as an Emerging Discipline
Anthropic, Google, and others have begun articulating context engineering as a distinct discipline—separate from prompt engineering, separate from fine-tuning.[1][7] The framing is right: what lands in the context window determines agent behavior more reliably than any other factor.[8]
But most current approaches still operate in what we'd call static context engineering: you configure system prompts, design RAG pipelines, set up tool descriptions, and tune retrieval parameters. The context shape is decided at design time and stays fixed during execution.
The Agent Mesh represents a step toward dynamic context engineering—systems that observe agent behavior in real time and adapt what context is available based on what the agent is actually doing. The context shape changes during execution, driven by the agent's trajectory.
The Shift Ahead
We don't think this replaces RAG or careful prompt design. Those remain essential. But trajectory-based context delivery adds a layer that's predictive rather than reactive, learned rather than configured, and collaborative rather than isolated. As agents become longer-running and more autonomous, this layer becomes increasingly important.
The feedback loop—sessions generating patterns that improve future sessions—is what makes this compound. Each repository that opts into the mesh becomes a richer knowledge environment over time. The context engineering isn't a one-time design effort. It's a continuously learning system.
We're still early. Pattern quality varies. Latency constraints limit matching depth. Utilization tracking provides signal but not certainty. But the trajectory is clear: context engineering will evolve from something you configure to something that learns. The Agent Mesh is our experiment in making that transition concrete.
References
- Anthropic Applied AI Team. "Effective context engineering for AI agents." Anthropic Engineering Blog, September 2025. anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Ji, Y. ("Peak"). "Context Engineering for AI Agents: Lessons from Building Manus." Manus AI Blog, 2025. manus.im/blog/Context-Engineering-for-AI-Agents
- Anthropic Engineering. "Effective harnesses for long-running agents." Anthropic Engineering Blog, November 2025. anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Kane, A. et al. "pgvector: Open-source vector similarity search for Postgres." github.com/pgvector/pgvector
- OpenAI. "New embedding models and API updates." OpenAI Blog, January 2024. openai.com/index/new-embedding-models-and-api-updates
- Lewis, P. et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." NeurIPS 2020. arxiv.org/abs/2005.11401
- Google. "Agent Development Kit: Making it easy to build multi-agent applications." Google Developers Blog, 2025. developers.googleblog.com/agent-development-kit
- Lutke, T. "I really like the term 'context engineering' over prompt engineering. It describes the core skill better." X (Twitter), June 2025. x.com/tobi/status/1935533422589399127